
728x90
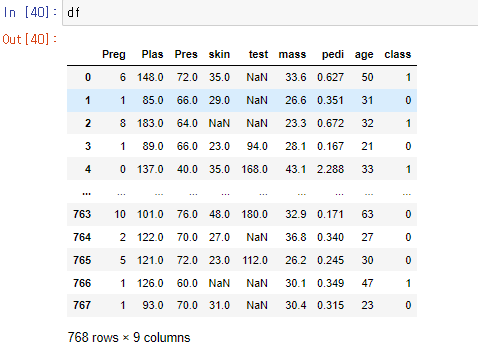
위와 같은 사진의 데이터프레임에서 당뇨병을 분류하는 모델을 만드는 도중
y값을 'class'컬럼으로 두었다. 당뇨병 환자는 1, 아닐 경우 0이다.
sb.countplot(data=df,x='class')
plt.show()위 코드를 작성하여 시각화 해보니

당뇨병인 사람의 데이터가 훨씬 적다.
그래서 up sampling 기법으로, 당뇨병 데이터를 늘려보았다.
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=2)
X,y=sm.fit_resample(X,y)
X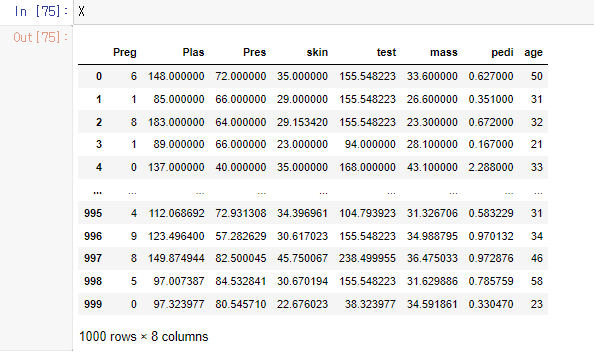
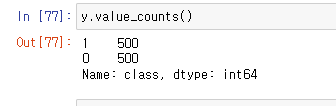
'class'의 밸류 값들이 1도 500 / 0도 500으로된 것을 확인할 수 있다.
이후
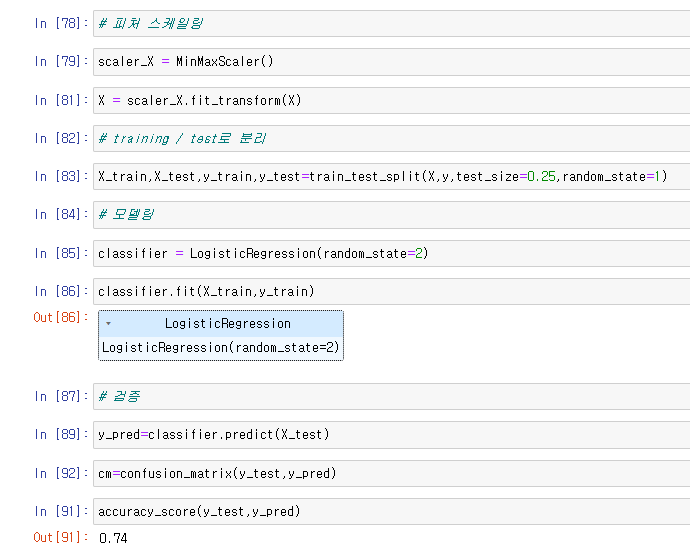
피처스케일링부터 검증까지 해주고 이를 seaborn의 heatmap으로 시각화까지 해보았다
sb.heatmap(data=cm,annot=True,cmap='RdPu',linewidths=0.7)
plt.show()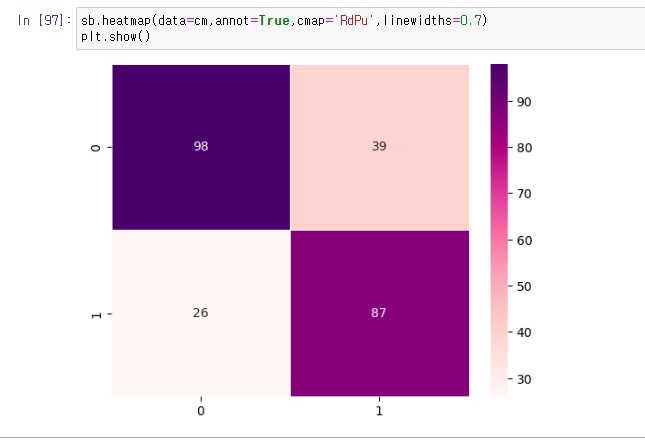
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 : Support Vector Machine SVM (0) | 2022.12.02 |
|---|---|
| 머신 러닝 : KNN알고리즘 (K-Nearest Neighbor) (0) | 2022.12.02 |
| 머신 러닝 : Logistic Regression , Confusion Matrix (0) | 2022.12.02 |
| 머신러닝 : Multiple Linear Regression (0) | 2022.12.01 |
| 머신러닝 : Linear Regression (0) | 2022.12.01 |