
728x90
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd필요 라이브러리를 import해줍니다.
df=pd.read_csv('../data/50_Startups.csv')
위 csv 파일을 읽어와서
각각의 피쳐를 분석하여, 어떤 신생 회사의 데이터가 있으면, 그 회사가 얼마의 수익을 낼 지 예측합니다. (투자를 해야 할지 말아야 할지)
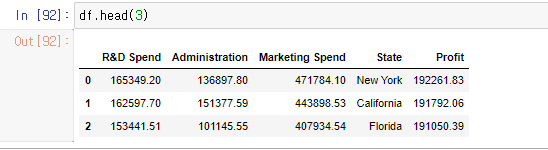
Nan을 확인합니다.

어떤 인공지능을 개발할지 X,y 값을 세팅해줍니다.
X=df.loc[:,'R&D Spend':'State']
y=df['Profit']문자열이 들어있는 컬럼이 있기때문에, 문자열 컬럼은 숫자로 바꿔줘야합니다.
문자열 컬럼이 카테고리컬 데이터인지 먼저 확인하고 알파벳 순으로 정렬합니다.
X['State'].describe()sorted(X['State'].unique())원 핫 인코딩 과정.
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformerct=ColumnTransformer([('encoder',OneHotEncoder(),[3])],remainder='passthrough')X=ct.fit_transform(X.values)
모두 숫자로 변경되었으니, train / test 데이터로 분리합니다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=1)인공지능 모델링 시작.
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train,y_train)y_pred=regressor.predict(X_test)
MSE를 구한 후 성능 평가 과정.
error = y_test - y_pred
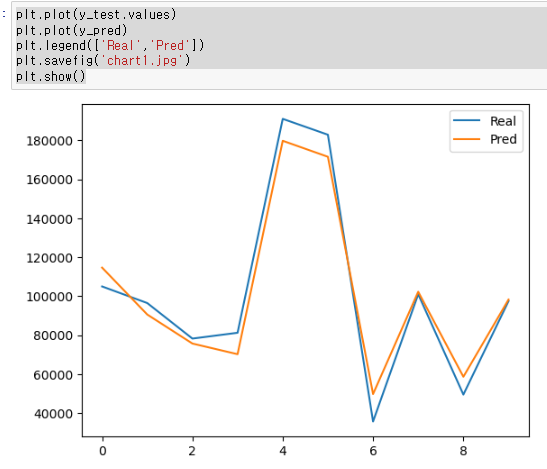
(error ** 2 ).mean() # MSE실제값(y_test.values)과 예측값(y_pred)의 데이터를 차트로 나타내봅니다.
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real','Pred'])
plt.savefig('chart1.jpg')
plt.show()
예제)
# 운영비는 15만달러, 마케팅비는 40만달러, 연구개발비는 13만달러이고,
# 회사는 Florida에 있다.
# 이 회사는 어람의 수익을 얻을 수 있을지 예측하시오.
new_data=np.array( [130000,150000,400000,'Florida'] )new_data=new_data.reshape(1,4)new_data=ct.transform(new_data).astype(float)regressor.predict(new_data)
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신 러닝 : Logistic Regression up sampling기법 imblearn.over_sampling SMOTE (0) | 2022.12.02 |
|---|---|
| 머신 러닝 : Logistic Regression , Confusion Matrix (0) | 2022.12.02 |
| 머신러닝 : Linear Regression (0) | 2022.12.01 |
| 머신 러닝 : Training / Test set , 트레이닝 용 / 테스트 용 데이터 나누기 train_test_split() (0) | 2022.12.01 |
| 머신러닝 : Feature Scaling , 피쳐 스케일링,StandardScaler,MinMaxScaler, 표준화,정규화 (0) | 2022.12.01 |