
728x90
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd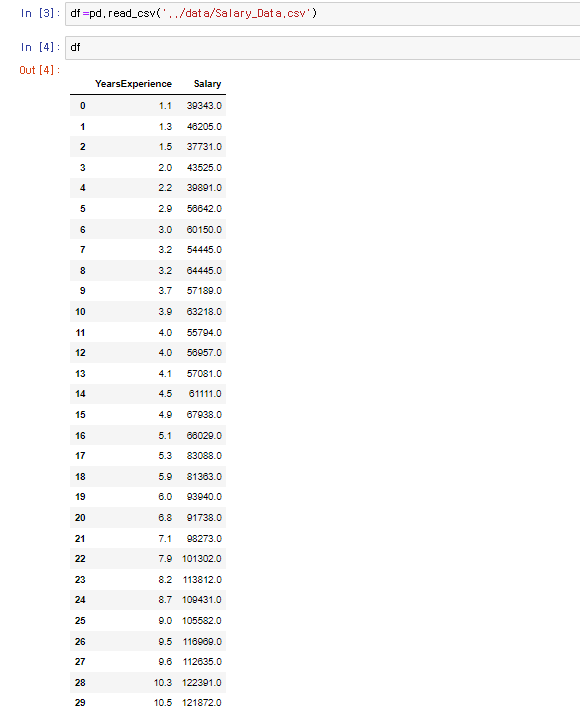
우선 사용할 라이브러리를 import해주고, 경력과 연봉의 관계분석을 통해, 누군가 입사 했을 때 그 사람의 경력에 맞는 현봉을 제시해줄수 있도록 경력과 연봉 컬럼에 데이터가 들어있는 Csv파일을 읽습니다.

이후 shape과 describe 함수로 기본적인 정보,수치를 확인해주고
1. NaN 확인 ( 결측치 확인 )
df.isna().sum()
2. X와 y로 분리
X=df.iloc[:,0].to_frame()y = df['Salary']
3. 문자열 데이터는 숫자로 바꿔주기.
위 데이터 프레임에는 문자열이 있지 않기 때문에 생략합니다.
4. 피쳐 스케일링
리니어 리그레션은 자체적으로 피처스케일링을 해줍니다. 따라서 우리가 피처스케일링을 할 필요가 없습니다.
5. Training / Test 셋으로 분리.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=1)
이렇게 사용할 준비가 끝났으면, 이제 모델링을 시작하겠습니다.
리니어 리그레션으로 모델링 => 이것을 사용하는 이유는 수치예측이라서입니다.
from sklearn.linear_model import LinearRegression# y = ax + b
# 랜덤으로 a와 b 셋팅
# fit함수를 실행하면, X_train,y_train 가지고
# 오차를 찾아서 오차가 최소가 되도록
# a와 b값을 셋팅한다!!
# y = 9332.94473799 * x + 25609.89799835482
regressor=LinearRegression()인공지능 학습시키기.
regressor.fit(X_train,y_train)regressor.coef_regressor.intercept_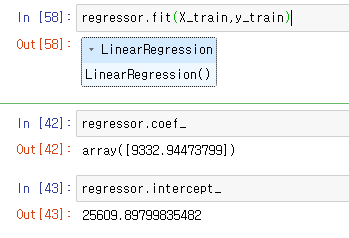
학습이 끝나면, 이 인공지능이 얼마나 똑똑한지 테스트를 해야합니다. 따라서 테스트용 데이터인 X_test로 테스트합니다.
y_pred=regressor.predict(X_test)
오차(error)의 정의 : 실제값 - 예측값
error = y_test - y_pred# 성능 측정을 하기 위해서는
# 그냥 오차를 사용하면, 부호때문에, 이상하게 계산이 된다.
# 따라서 성능측정을 위해서는, 부호를 없개ㅣ 위해서
# 오차를 제곱해준다.
error ** 2이후 제급한 오차의 평균을 구해줍니다.
( error ** 2 ).mean()# 오차를 구하고, 오차를 제곱한 후에, 평균을 구한 값
# mean squared error => MSE
# MSE로 성능평가를 해서, 수치가 작을 수록 좋은 인공지능이라는 뜻.
이후 실제값과 예측값을 차트로 그려봅니다.
plt.plot(y_test.values)
plt.plot(y_pred)
plt.legend(['Real','Pred'])
plt.show()

'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신 러닝 : Logistic Regression , Confusion Matrix (0) | 2022.12.02 |
|---|---|
| 머신러닝 : Multiple Linear Regression (0) | 2022.12.01 |
| 머신 러닝 : Training / Test set , 트레이닝 용 / 테스트 용 데이터 나누기 train_test_split() (0) | 2022.12.01 |
| 머신러닝 : Feature Scaling , 피쳐 스케일링,StandardScaler,MinMaxScaler, 표준화,정규화 (0) | 2022.12.01 |
| 머신러닝 : 원 핫 인코딩 One Hot Encoding (0) | 2022.12.01 |