
728x90
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd다음처럼 카테고리가 레이블링 되어 있는 데이터가 존재합니다.

새로운 데이터가 생겼을때, 이를 어디로 분류해야 할까요?
왜 빨간색으로 분류를 했을까요.
내 주위에 몇개의 이웃을 확인해 볼것인가를 결정한다. => K
새로운 데이터가 발생 시, Euclidean distance 에 의해서, 가장 가까운 K 개의 이웃을 택한다.
K 개의 이웃의 카테고리를 확인한다.
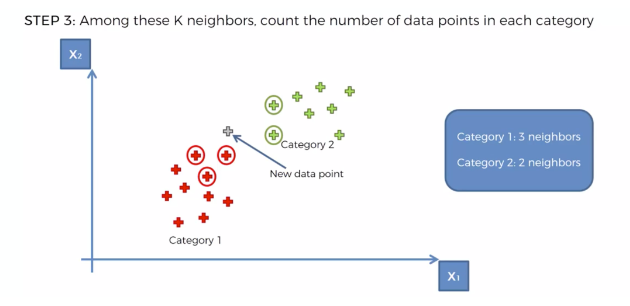
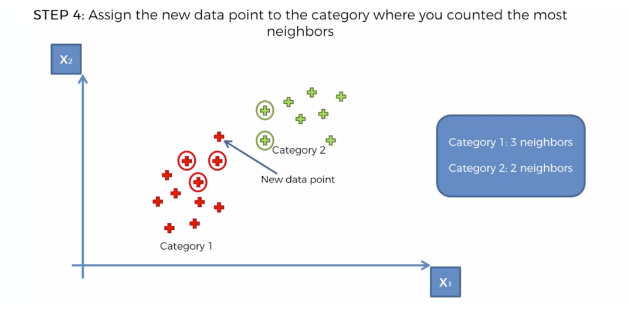
카테고리의 숫자가 많은 쪽으로, 새로운 데이터의 카테고리를 정해버린다.
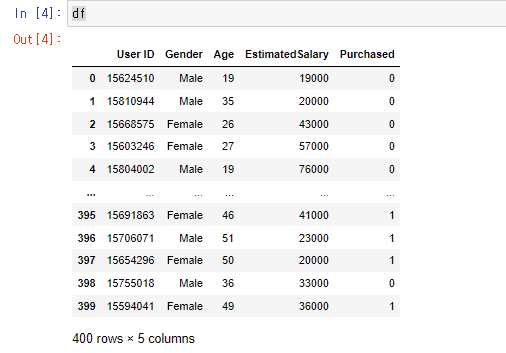
df=pd.read_csv('../data/Social_Network_Ads.csv')
df데이터 프레임을 읽어옵니다.
df.isna().sum()결측치 확인
y=df['Purchased']
X=df.loc[:,['Age','EstimatedSalary']]X,y 분리
from sklearn.preprocessing import MinMaxScaler
scaler_X=MinMaxScaler()
X=scaler_X.fit_transform(X)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.25,random_state=1)
from sklearn.neighbors import KNeighborsClassifier
# 가장 가까운 5개 데이터로 분류
classifier = KNeighborsClassifier(n_neighbors=3)
classifier.fit(X_train,y_train)
y_pred=classifier.predict(X_test)모델링 과정

from sklearn.metrics import confusion_matrix, accuracy_score
cm=confusion_matrix(y_test,y_pred)
cm
accuracy_score(y_test,y_pred)
confusion_matrix , accuracy_score 확인.
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.legend()
plt.show()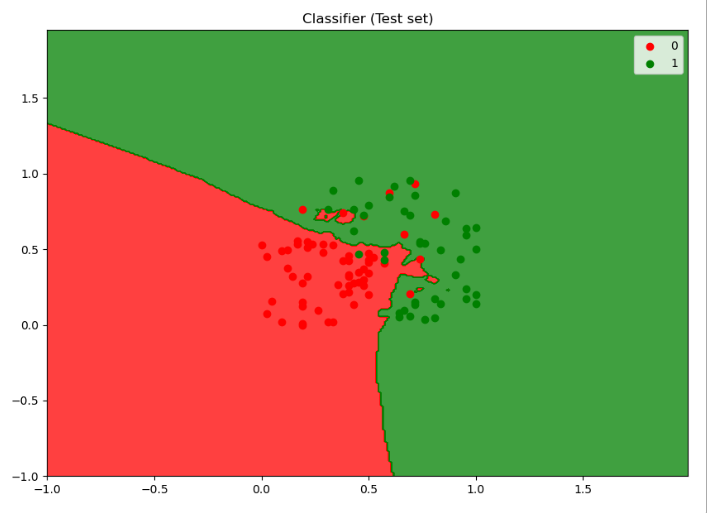
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 : BREAST CANCER CLASSIFICATION 예제풀이 (0) | 2022.12.02 |
|---|---|
| 머신러닝 : Support Vector Machine SVM (0) | 2022.12.02 |
| 머신 러닝 : Logistic Regression up sampling기법 imblearn.over_sampling SMOTE (0) | 2022.12.02 |
| 머신 러닝 : Logistic Regression , Confusion Matrix (0) | 2022.12.02 |
| 머신러닝 : Multiple Linear Regression (0) | 2022.12.01 |