
728x90
라이브러리 임포트
import pandas as pd # Import Pandas for data manipulation using dataframes
import numpy as np # Import Numpy for data statistical analysis
import matplotlib.pyplot as plt # Import matplotlib for data visualisation
import seaborn as sb # Statistical data visualization
%matplotlib inlinefrom sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer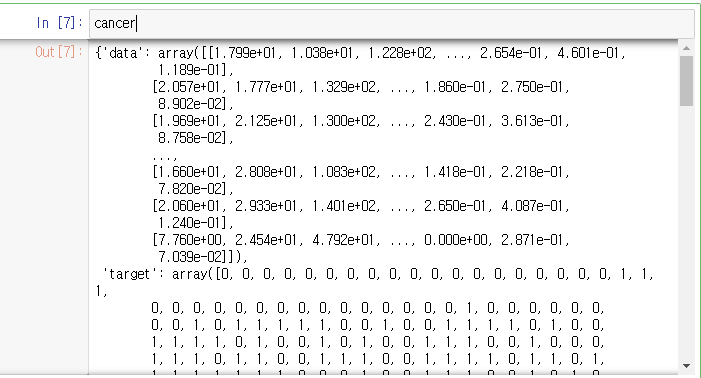
cancer.keys()print(cancer['feature_names'])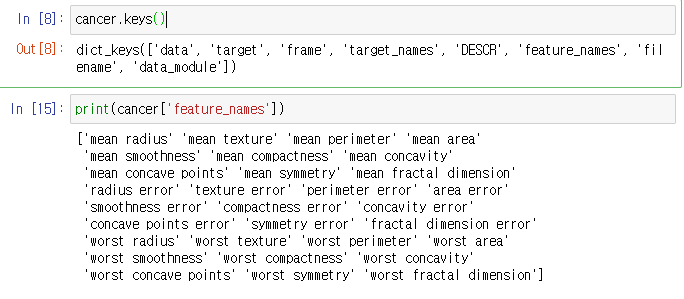
np.c_ 와 np.append
col_names=np.append(cancer['feature_names'],'target')
col_names
cancer_data=np.c_[ cancer['data'],cancer['target'] ]
df=pd.DataFrame(data= cancer_data,columns=col_names)
df
위 과정을 통해 데이터프레임을 만들어줍니다.
이후 pairplot을 이용해서, 각 컬럼의 관계를 파악해보겠습니다.
sb.pairplot(data=df,hue='target',vars=['mean radius','mean texture','mean perimeter','mean smoothness'])
plt.show()
상관 계수 결과를, 히트맵으로 보여줍니다.
sb.heatmap(data=df_corr,cmap='coolwarm',annot=True,fmt='.1f',linewidths=0.8,vmin=-1,vmax=1)
plt.show()
df_all=df.corr()
plt.figure(figsize=(20,10))
sb.heatmap(data=df_all,cmap='coolwarm',annot=True,fmt='.1f',linewidths=0.5,vmin=-1,vmax=1)
plt.show()
이후 모델링 과정.
df.isna().sum()결측치 확인
y=df['target']
X=df.iloc[:,0:-2+1]X,y 분리
from sklearn.preprocessing import StandardScaler
scaler_X=StandardScaler()
X=scaler_X.fit_transform(X)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2,random_state=1)
from sklearn.svm import SVC
classifier1 = SVC(kernel='linear',random_state=2,C=1.5,gamma=0.05)
classifier2 = SVC(kernel='rbf',random_state=2)
classifier1.fit(X_train,y_train)
classifier2.fit(X_train,y_train)
검증 과정
y_pred1=classifier1.predict(X_test)
y_pred2=classifier2.predict(X_test)
from sklearn.metrics import confusion_matrix,accuracy_score
confusion_matrix(y_test,y_pred1)
accuracy_score(y_test,y_pred1)
confusion_matrix(y_test,y_pred2)
accuracy_score(y_test,y_pred2)
grid search // GridSearchCV이용하여 가장 좋은 grid 값 찾기
param_grid = {'kernel':['linear','rbf','poly'],'C':[0.1,1,10],'gamma':[0.01,0.1,1]}
from sklearn.model_selection import GridSearchCV
grid=GridSearchCV( SVC(),param_grid,refit=True,verbose=4 )
grid.fit(X_train,y_train)
classifier = grid.best_estimator_
classifier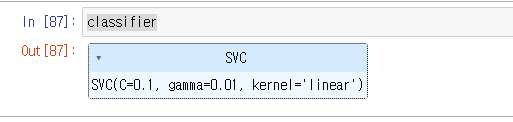
grid.best_params_
grid.best_score_
y_pred = classifier.predict(X_test)
confusion_matrix(y_test,y_pred)
accuracy_score(y_test,y_pred)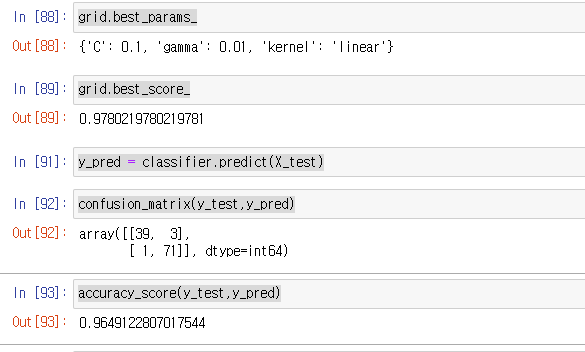
'인공지능 > 머신러닝' 카테고리의 다른 글
| 머신러닝 : K-Means Clustering (0) | 2022.12.05 |
|---|---|
| 머신러닝 : Decision Tree (0) | 2022.12.02 |
| 머신러닝 : Support Vector Machine SVM (0) | 2022.12.02 |
| 머신 러닝 : KNN알고리즘 (K-Nearest Neighbor) (0) | 2022.12.02 |
| 머신 러닝 : Logistic Regression up sampling기법 imblearn.over_sampling SMOTE (0) | 2022.12.02 |