
728x90
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd우선 사용할 라이브러리들을 임포트 해줍니다.
df=pd.read_csv('../data/Mall_Customers.csv')
df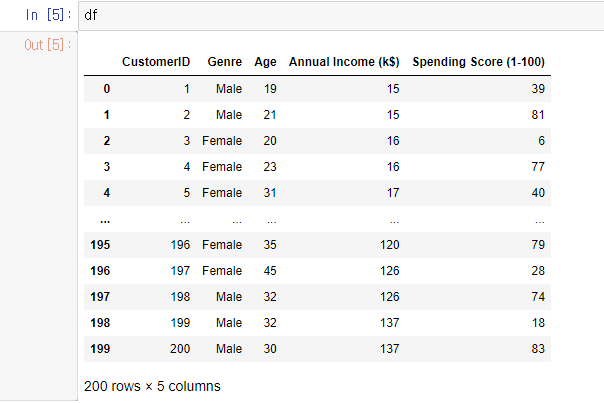
데이터프레임을 읽어온 후 변수 df로 저장
df.isna().sum()
결측치 확인
X = df.iloc[:,3:]X 데이터 셋팅
Dendrogram 을 그리고, 최적의 클러스터 갯수를 찾아보자.
import scipy.cluster.hierarchy as sch
sch.dendrogram(sch.linkage(X,method='ward'))
plt.title('Dendrogram')
plt.xlabel('Custromers')
plt.ylabel('Euclidean Distances')
plt.show()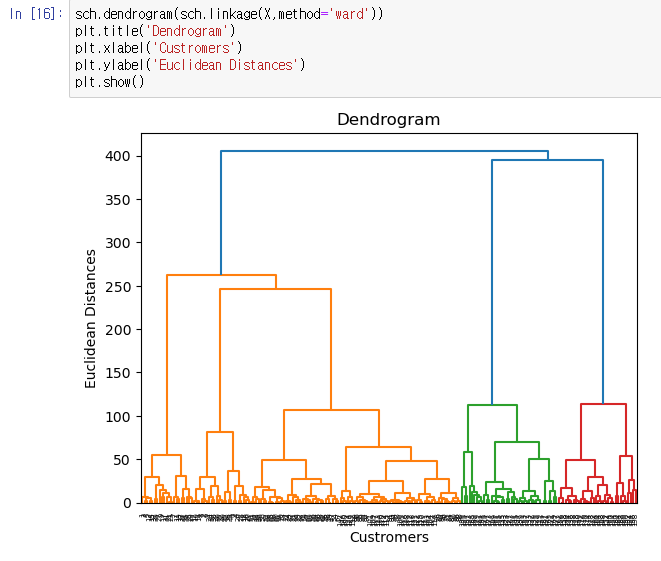
모델링하고, df에 새로운 컬럼 'Group'으로 저장
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters= 5,)
y_pred=hc.fit_predict(X)
df['Group'] = y_pred
df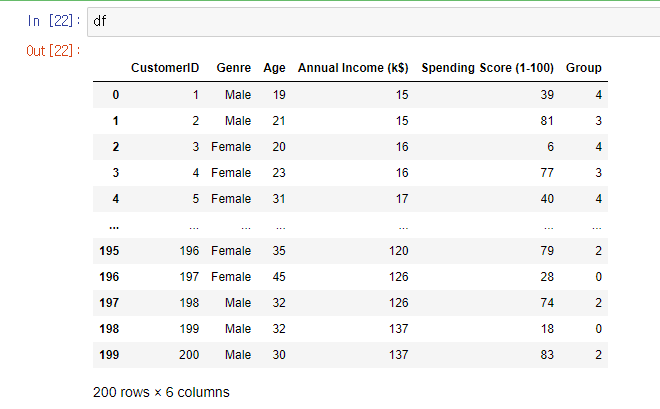
그루핑 정보를 확인
plt.figure(figsize=[12,8])
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
'인공지능 > 머신러닝' 카테고리의 다른 글
| 지도학습 vs 비지도학습 쉽게 이해하기 (0) | 2023.08.04 |
|---|---|
| 머신러닝 : K-Means Clustering (0) | 2022.12.05 |
| 머신러닝 : Decision Tree (0) | 2022.12.02 |
| 머신러닝 : BREAST CANCER CLASSIFICATION 예제풀이 (0) | 2022.12.02 |
| 머신러닝 : Support Vector Machine SVM (0) | 2022.12.02 |