
728x90
우선 사용할 라이브러리들 import후 데이터 프레임을 불러옵니다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
%matplotlib inlinedf = pd.read_csv('Churn_Modelling.csv')
1. 결측치 확인
df.isna().sum()위 데이터 프레임에는 결측치가 없었기 때문에 nan 처리를 안 하였습니다.
2. X와 y로 분리
X=df.iloc[:,3:-1]
y=df['Exited']3. 문자열 데이터 처리 ( LabelEncoder , OneHotEncoder)
X['Geography'].nunique()X['Gender'].nunique()
어떤 2개 이하이면 레이블 인코딩을 , 아니라면 원핫 인코딩을 하기 위해 유니크한 값을 확인하고
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer필요한 라이브러리 임포트 후
레이블 인코딩부터 진행
label_encoder = LabelEncoder()
X['Gender']=label_encoder.fit_transform(X['Gender'])원 핫 인코딩 진행
ct=ColumnTransformer([('encoder', OneHotEncoder(),[1])],remainder='passthrough')
X=ct.fit_transform(X.values)4. dummy variable trap
X_df=pd.DataFrame(X)X_df.drop(0,axis=1,inplace=True) # france 컬럼을 삭제해도 3개의 데이터를 모두 나타낼 수 있음.X = X_df.values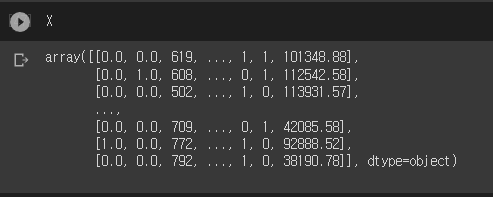
5. 피쳐 스케일링
머신러닝과 다른 점은 딥러닝은 무조건 피쳐스케일링 해야한다. 매우 중요하다.
from sklearn.preprocessing import MinMaxScalerscaler_X = MinMaxScaler()X=scaler_X.fit_transform(X)
6. 학습용과 테스트용으로 데이터 나누기 ( train_test_split )
from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)
7. 모델링 과정
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Densemodel = Sequential()model.add( Dense(units = 6, activation='relu',input_shape=(11,) ) )2개로 분류 => sigmoid
model.add(Dense(units=1,activation='sigmoid'))
8. 컴파일(Compile) 과정
컴파일이란, 옵티마이저(optimizer)와 로스펑션 (loss function 오차함수,손실함수)
2개로 분류하는 문제의 loss는 'binary_crossentropy'
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=[ 'accuracy'])
9. 학습 과정
주의점 : 학습 코드를 실행한 후에, 다시 학습하고 싶을 때는, 모델링 부분부터 다시 실행해야한다.
model.fit(X_train,y_train,batch_size=10,epochs=20)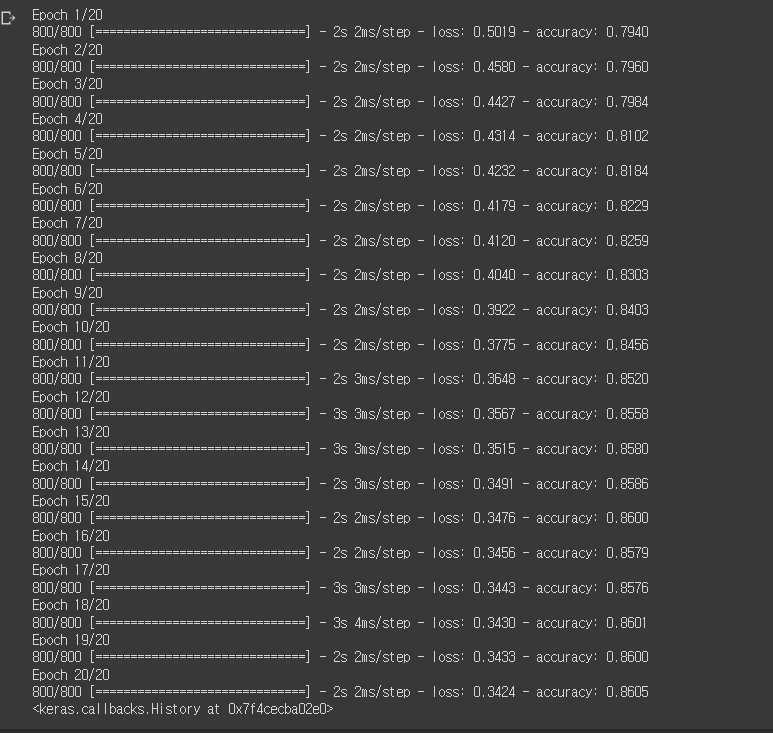
10. 평가 과정
model.evaluate(X_test,y_test)
컨퓨전 매트릭스를 확인하여, 어떤 문제를 잘 맞추고 못 맞추는지 확인
from sklearn.metrics import confusion_matrix,accuracy_scorey_pred=model.predict(X_test)y_pred=(y_pred > 0.5).astype(int)cm=confusion_matrix(y_test,y_pred)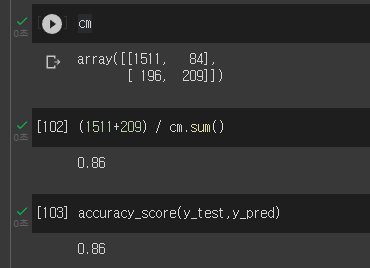
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 : Tensorflow로 리그레션 문제 모델링 하는 방법 (0) | 2022.12.28 |
|---|---|
| 딥러닝 : GridSearch를 이용한 최적의 하이퍼 파라미터 찾기 (0) | 2022.12.27 |
| 딥러닝 : Dummy variable trap (0) | 2022.12.27 |
| 딥러닝 : fit 함수에서 배치 사이즈 (batch_size= )와 에포크(epochs=) (0) | 2022.12.27 |
| 딥러닝 : 뉴런의 정의 (0) | 2022.12.27 |