
728x90
우선 사용할 라이브러리들 import후 데이터 프레임을 불러옵니다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as snscsv 파일을 읽기 위해, 구글 드라이브 마운트를 진행합니다.
from google.colab import drive
drive.mount('/content/drive')working directory 를, 현재의 파일이 속한 폴더로 셋팅합니다.
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks/ml_plus/data')데이터 프레임을 불러옵니다.
df = pd.read_csv('Car_Purchasing_Data.csv',encoding='ISO-8859-1')
1. 결측치 확인
df.isna().sum()2. X와 y로 분리
X = df.iloc[:,3:-1]
y = df['Car Purchase Amount']3. 피쳐 스케일링
머신러닝과 다른 점은 딥러닝은 무조건 피쳐스케일링 해야한다. 매우 중요하다.
X와 y의 스케일러를 따로 만들어줍니다.
from sklearn.preprocessing import MinMaxScalerscaler_X = MinMaxScaler()
X=scaler_X.fit_transform(X.values)scaler_y = MinMaxScaler()
scaler_y.fit_transform(y.values)
다음과 같이 에러가 발생하는 것을 확인할 수 있습니다.
학습을 위해서, y의 shape을 변경하겠습니다.
y.values.reshape(500,1)y_scaled=scaler_y.fit_transform(y.values.reshape(500,1))새로운 변수 y_scaled에 저장.
6. 학습용과 테스트용으로 데이터 나누기 ( train_test_split )
테스트 사이즈는 25%로 랜덤스테이트는 50 으로 셋팅하겠습니다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y_scaled,test_size=0.25,random_state=50)7. 모델링 과정
import tensorflow.keras
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import MinMaxScaler옵티마이저는 'adam' 으로 하고, 로스펑션은 'mse','mae' 로 셋팅하여 컴파일 하겠습니다.
def build_model() :
model = Sequential()
model.add(Dense(units=5,activation='relu',input_shape=(5,)))
model.add(Dense(units=25,activation='relu'))
model.add(Dense(units=10,activation='relu'))
model.add(Dense(units=1,activation='linear'))
model.compile(optimizer='adam',loss='mse',metrics=['mse','mae'])
return modelmodel = build_model()8. 학습 과정
주의점 : 학습 코드를 실행한 후에, 다시 학습하고 싶을 때는, 모델링 부분부터 다시 실행해야한다.
batch_size는 10, epochs는 20으로 학습하겠습니다.
model.fit(X_train,y_train,batch_size=10,epochs=20)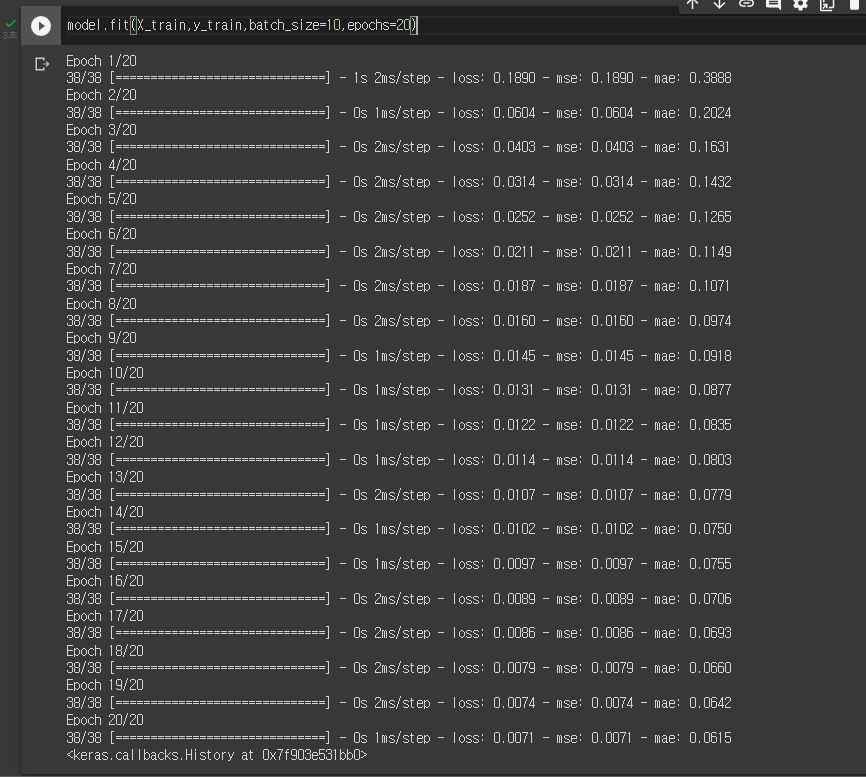
9. 평가, 예측
model.evaluate(X_test,y_test)y_pred=model.predict(X_test)error = y_test - y_pred
(error ** 2).mean()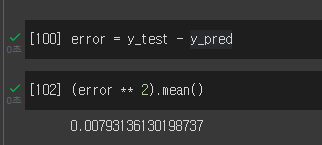
실제값과 예측값을 plot으로 나타내어 시각화
plt.plot(y_test)
plt.plot(y_pred)
plt.show()
10. 실습
새로운 고객 데이터가 있습니다. 이 사람들은 차량을 얼마정도 구매 가능한지 예측하시오.
첫번 째 고객은 여자이고, 나이는 38, 연봉은 90000, 카드빚은 2000, 순자산은 500000이고
두번 째 고객은 남자이고, 나이는 27, 연봉은 30000, 카드빚은 10000, 순자산은 300000일 때,
어느정도의 차량을 구매할 수 있을지 예측해보겠습니다.
new_data=np.array([[0,38,90000,2000,500000],[1,27,30000,10000,300000]]) # 새로운 array를 만들고 new_data라는 변수에 저장
new_data=new_data.reshape(2,5) # 위에서 2차원으로 진행했기 때문에, reshape을 이용하여 2행 5열로 만들어줍니다
new_data=scaler_X.transform(new_data) # 위에선 fit_transform을 했지만, 이미 학습은 되어있는 상태이기 때문에 transfrom만 해줍니다
y_pred3=model.predict(new_data) # 예측한 후 y_pred3이라는 변수로 저장
scaler_y.inverse_transform(y_pred3) # 표준 값을 실제 원본 값으로 복원하는 과정!!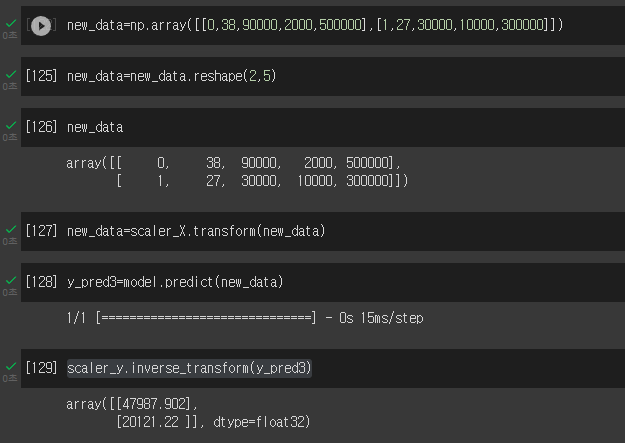
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 : validation data와 Callback(EarlyStopping Library) 사용법 (0) | 2022.12.28 |
|---|---|
| 딥러닝 : learning rate를 optimizer에 셋팅하기. (0) | 2022.12.28 |
| 딥러닝 : GridSearch를 이용한 최적의 하이퍼 파라미터 찾기 (0) | 2022.12.27 |
| 딥러닝 : Dummy variable trap (0) | 2022.12.27 |
| 딥러닝 : tensorflow로 분류의 문제 모델링 하는 방법 (0) | 2022.12.27 |