
Yolo v8을 통해 학습을 완료하게 되면 C:\Users\your_path\runs\detect\train 이라는 폴더에 아래 사진과 같이 파일들이 저장되는 것을 확인할 수 있다.

각각의 파일들이 어떠한 정보를 가지고 있는지 자세하게 살펴보려고한다.
confusion_matrix.png
이 파일은 혼동 행렬(Confusion Matrix)를 시각화한 것입니다.
혼동 행렬은 분류 모델의 성능을 평가하는 데 사용되며, 모델이 예측한 클래스와 실제 클래스 간의 관계를 보여줍니다.
행은 실제 클래스를, 열은 예측된 클래스를 나타냅니다.
대각선 값들은 정확하게 분류된 인스턴스를 나타내며, 대각선 이외의 요소들은 잘못 분류된 인스턴스를 나타냅니다.
- 행(Row): 이는 실제 클래스(Actual Class)를 나타냅니다. 예를 들어, 어떤 이미지가 '고양이' 클래스에 속한다면, 이 이미지는 '고양이' 행에 위치합니다.
- 열(Column): 이는 예측된 클래스(Predicted Class)를 나타냅니다. 동일한 '고양이' 이미지가 모델에 의해 '개'로 예측되었다면, 이 이미지는 '개' 열에 위치합니다.
confusion_matrix_normalized.png
정규화된 혼동 행렬을 시각화한 것입니다.
각 셀의 값을 해당 행의 전체 개수로 나눔으로써 정규화합니다.
이렇게 하면 특정 클래스의 샘플 수가 많을 때 발생하는 불균형을 보정할 수 있습니다.

F1_curve.png
이 파일은 모델의 F1 점수를 시각화한 것입니다.
F1 점수는 분류 모델의 성능을 나타내는 메트릭 중 하나로, 정밀도(Precision)와 재현율(Recall)의 조화 평균입니다.
이 값은 0과 1 사이의 값을 가지며, 1에 가까울수록 모델의 성능이 좋다는 것을 의미합니다.
이 그래프에서는 여러 임계값에 대한 F1 점수를 볼 수 있습니다.


labels.jpg
이 파일은 각 클래스 레이블에 해당하는 객체를 시각화한 것입니다.
이는 학습 데이터 세트의 샘플을 보여주며, 모델이 어떤 객체를 어떻게 인식하는지를 이해하는 데 도움이 됩니다.
labels_correlogram.jpg
이 파일은 라벨 간의 상관 관계를 나타냅니다.
만약 두 라벨이 같은 이미지 내에 동시에 자주 등장한다면, 이 두 라벨 사이에 강한 양의 상관 관계가 있다고 할 수 있습니다.
반대로, 한 라벨이 달느 라벨이 없는 이미지에 자주 등장한다면, 이 두 라벨 사이에는 음의 상관 관계가 있다고 볼 수 있습니다.
이 정보는 특정 라벨이 다른 라벨과 얼마나 밀접하게 관련되어 있는지를 이해하는데 도움이 됩니다.

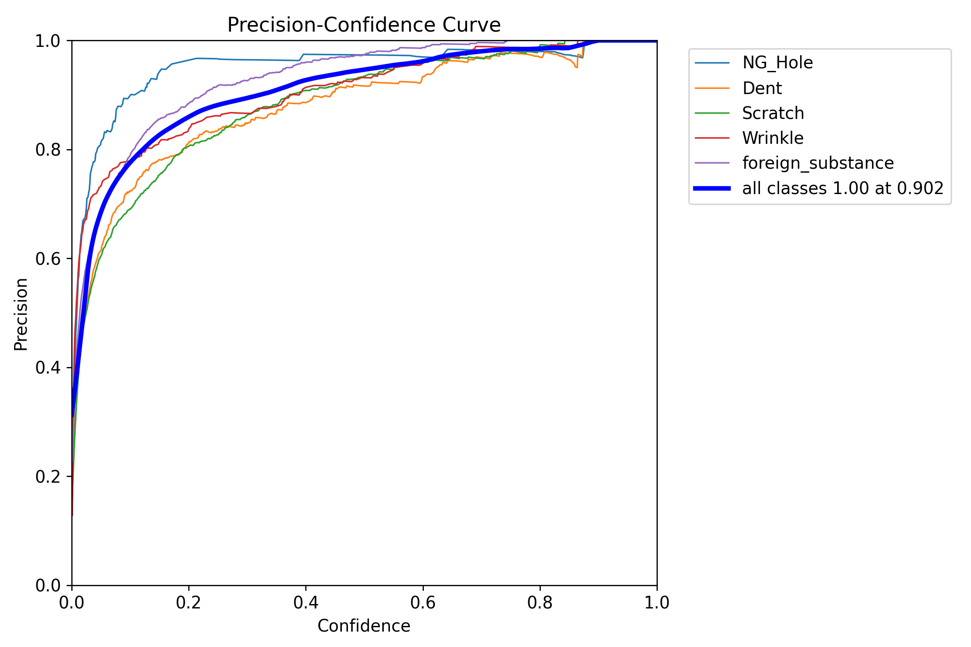
P_curve.png
이 파일은 학습 과정에서 각 에폭마다 정밀도(Precision)의 변화를 나타냅니다.
정밀도는 모델이 True로 예측한 것 중에서 실제로 True인 비율을 나타냅니다.
즉,모델의 예측이 얼마나 정확한지를 나타냅니다.
이 그래프는 모델이 학습을 진행하면서 예측의 정확성이어떻게 변화하는지를 보여줍니다.
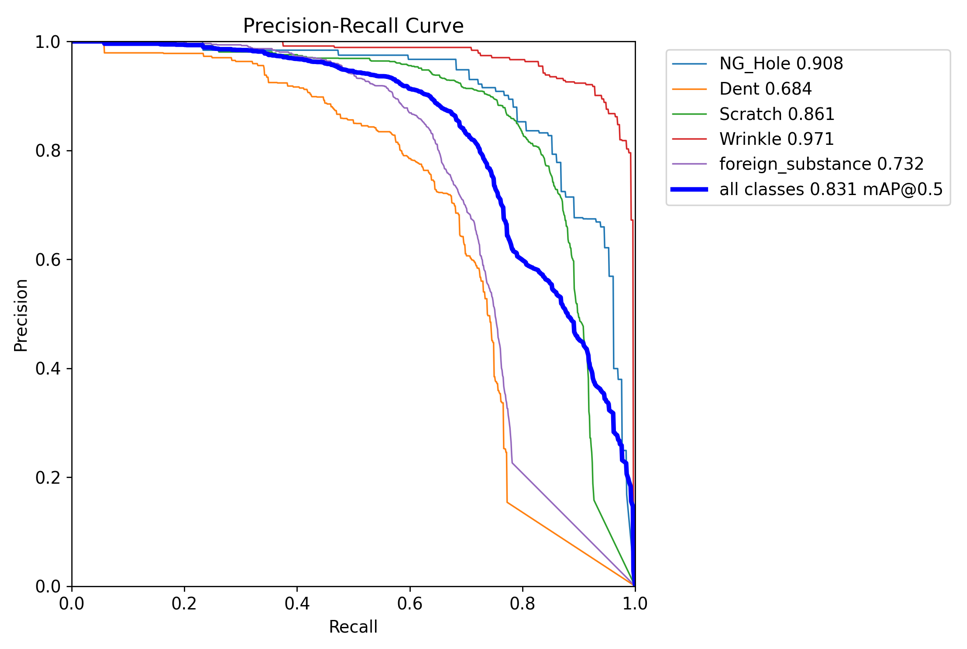
PR_curve.png
이 파일은 정밀도-재현율 ( Precision-Recall ) 곡선을 나타냅니다.
정밀도와 재현율은 모델의 성능을 평가하는데 중요한 두가지 지표입니다.
이 곡선은 모델이 다양한 분류 임계값에서 어떻게 작동하는지를 보여줍니다.
이는 불균형한 클래스 분포를 가진 데이터셋에서 모델의 성능을 평가하는데 특히 유용합니다.
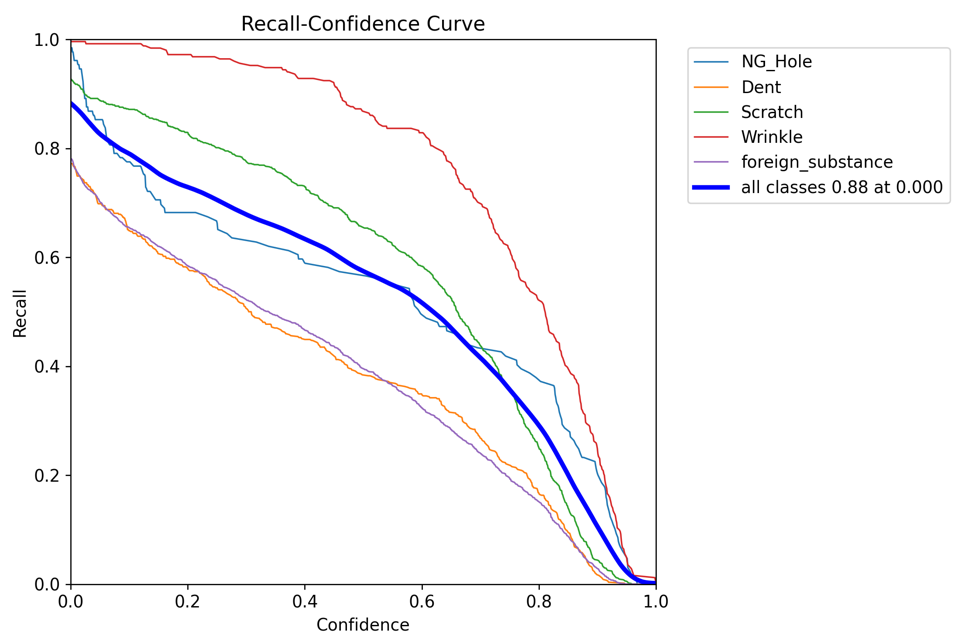
R_curve.png
이 파일은 학습 과정에서 각 에폭마다 재현율( Recall )의 변화를 나타냅니다.재현율은 실제 True인 것 중에서 모델이 True로 예측한 비율을 나타냅니다.즉, 모델이 실제 Ture인 것을얼마나 잘 찾아내는지를 나타냅니다.이 그래프는 모델이 학습을 진행하면서 True를 찾아내는 능력이 어떻게 변화하는지를 보여줍니다.
args.yaml
이 파일은 훈련을 실행할 때 사용된 매개변수와 설정을 포함하고있습니다.
YOLO 훈련 스크립트에 전달된 모든 커맨드 라인 인수를 YAML 형식으로 저장합니다.
이는 훈련 세션을 나중에 재현하거나, 어떤 설정을 사용하여 훈련되었는지 확인하고자 할 때 유용합니다.
results.csv
이 파일은 에폭마다의 훈련 및 검증 성능 메트릭을 CSV 형식으로 포함하고있습니다.
이러한 메트릭에는 손실(loss), 정밀도(precision), 재현율(recall), F1 점수 등이 포함됩니다.
이 파일은 훈련 과정을 분석하고, 학습 곡선을 그리고, 최적의 모델을 결정하는데 도움이 됩니다.
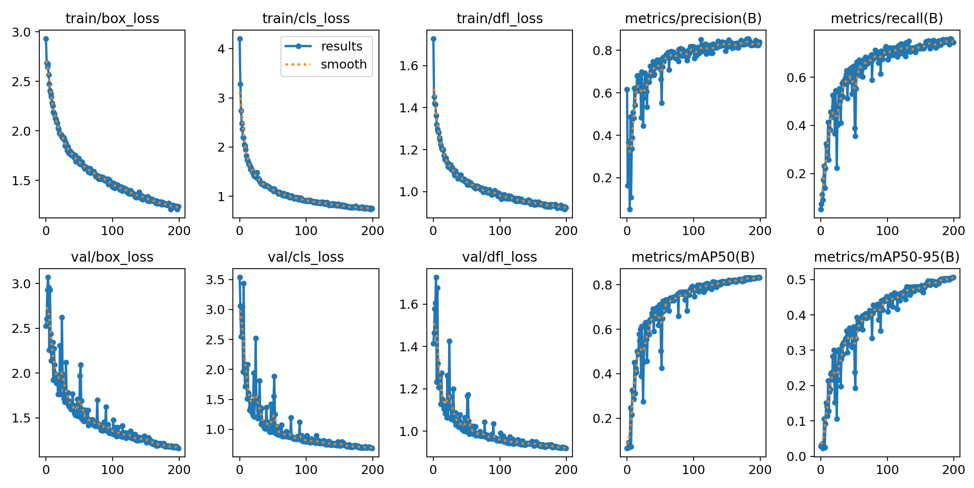
results.png
이 파일은 위에서 설명한 results.csv에서 얻은 데이터를 기반으로 학습곡선을 보여줍니다.
이 곡선은 훈련 및 검증 세트에 대한 손실 및 성능 메트릭의 변화를 보여주므로, 모델의 학습 과정을 시각적으로 이해하는데 도움이 됩니다.
이 그림은 과적합이나 학습속도와 같은 문제를 진단하는데 도움이 됩니다.
best.pt와 last.pt
- best.pt : 이 파일은 검증 데이터셋에서 가장 낮은 손실을 기록한 에폭에서의 모델 가중치를 저장합니다.
즉, 이 파일은 학습 과정 동안 가장 " 최고 "의 성능을 보였던 모델 상태를 나타냅니다.
일반적으로 이 모델은 가장 일반화된 성능을 보일 가능성이 높습니다.
- last.pt: 이 파일은 학습 프로세스가 끝난 후의 마지막 에폭에서의 모델 가중치를 저장합니다. 이 모델은 최신의 상태를 나타내지만, 반드시 최적의 서능을 보장하지는 않습니다.
따라서, 일반적으로 실제로 모델을 배포하거나 사용할 때는 'best.pt'파일을 사용하는 것이 좋습니다. 'last.pt'파일은 학습 과정의 진행 상황을 확인하거나 필요에 따라 추가적인 학습을 계속하기 위한 용도로 사용할 수 있습니다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| Anomalib: 왜 비지도학습인가? (0) | 2023.08.04 |
|---|---|
| Yolov8 - 테스트 동영상으로 예측하기 (0) | 2023.06.01 |
| DarkLabel 사용법 (0) | 2023.05.31 |
| Yolov8 - 내 커스텀 데이터를 이용해 학습하기 / 훈련 데이터와 검증 데이터로 나누기 (0) | 2023.05.31 |
| 딥러닝 : Time Series 데이터를 처리할 때 사용하는 resample() (0) | 2023.01.03 |