
728x90
모델링
이미지는 300X300 칼라 이미지다. 간단한 모델링 하기. 사진의 결과는 2개중의 하나이므로, 맨 마지막 액티베이션 함수는 'sigmoid' 사용
import tensorflow as tf
from keras.layers import Dense,Flatten,Conv2D,MaxPooling2D
from keras.models import Sequential필요 라이브러리 임포트
def build_model() :
model = Sequential()
model.add(Conv2D(16,(3,3),activation='relu',input_shape=(300,300,3)))
model.add(MaxPooling2D((2,2),2))
model.add(Conv2D(32,(3,3),activation='relu'))
model.add(MaxPooling2D((2,2),2))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(MaxPooling2D((2,2),2)) ## CNN
model.add(Flatten())
model.add(Dense(512,'relu'))
model.add(Dense(1,'sigmoid'))
model.compile('rmsprop','binary_crossentropy',['accuracy']) # ANN
return modelmodel = build_model()모델 변수 저장 후 summary확인
model.summary()
Data Preprocessing
# 아직 학습할 준비가 다 되지 않았다.
# 왜냐하면 fit 함수에 들어가는 데이터는
# 넘파이 어레이가 들어가야한다.
# 하지만 우리가 가지고있는 데이터는 이미지파일(png)이다.
# 따라서 현재 상태로는 fit함수를 이용한 학습이 불가능하다.
# 이미지파일을 넘파이 어레이로 변환시켜주는 ImageDataGenerator 라이브러리를 사용한다.
from keras.preprocessing.image import ImageDataGenerator필요 라이브러리 import
train_datagen = ImageDataGenerator(rescale=1/255.0) # rescale 파라미터를 이용해서 피쳐스케일링한 결과를 변수로 저장
validation_datagen = ImageDataGenerator(rescale=1/255.0)# 라이브러리를 변수로 만들었으면 그 다음 할 일은
# 이미지가 들어있는 디렉토리의 정보와 이미지 사이즈 정보와 몇 개로 분류할지 정보를
# 알려준다.
# 넘파이의 target_size와 model의 input_shape은 가로 세로가 같아야한다.
# class_mode는 2개로 분류할 땐 'binary', 3개 이상일 땐 categorical 사용.
train_generator=train_datagen.flow_from_directory('/tmp/horse-or-human',target_size=(300,300),
class_mode='binary')validation_generator=validation_datagen.flow_from_directory('/tmp/validation-horse-or-human',(300,300),class_mode='binary')
각 1027,256의 이미지를 찾았고, 2개의 class로 나뉘어져있는 것을 컴퓨터가 확인.
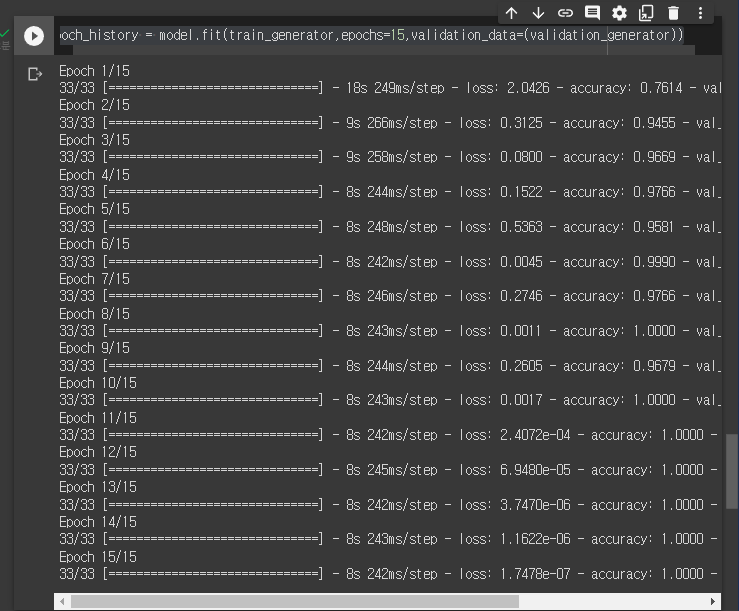
학습과 평가
epoch_history = model.fit(train_generator,epochs=15,validation_data=(validation_generator))이 전 게시글 들에서는 fit 안에 X_train,y_train,X_test,y_test 이런 식으로 집어넣었지만,
training값의 이미지와 정답이 모두 위에서 만든 train_generator , validation_generator에 들어있기 때문에 위 코드와
같이 작성을 해준다
위 결과를 시각화 하면
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.legend(['train','validation'])
plt.show()
신규 데이터 예측

위 사진으로 예측을 해보겠습니다.
이미지파일을 입력받아 예측하는 코드
import numpy as np
from google.colab import files
from tensorflow.keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys() :
path = '/content/' + fn
img = image.load_img(path, target_size=(300,300))
x = image.img_to_array(img) / 255.0
print(x)
print(x.shape)
x = np.expand_dims(x, axis = 0)
print(x.shape)
images = np.vstack( [x] )
classes = model.predict( images, batch_size = 10 )
print(classes)
if classes[0] > 0.5 :
print(fn + " is a human")
else :
print(fn + " is a horse")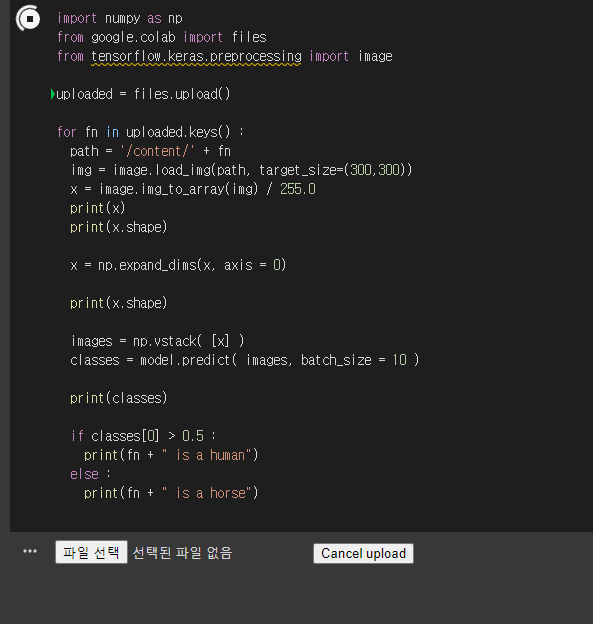

말이라고 예측한 것을 확인
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 : 원본 파일을 Train / Test 파일로 분리하여 사용하는 방법과 디렉토리를 만드는 방법 (0) | 2022.12.30 |
|---|---|
| 딥러닝 : 이미지 데이터 증강 / Image Augmentation (0) | 2022.12.30 |
| CNN의 convolution,Stride,Padding,Pooling / feature map의 사이즈를 구하는 공식 (0) | 2022.12.29 |
| 딥러닝 : 레이블링된 y값을 원핫 인코딩으로 바꾸기 tf.keras.utils.to_categorical() / Mnist 손글씨 숫자 예측 (0) | 2022.12.29 |
| 딥러닝 : Tensorflow의 모델을 저장하고 불러오는 방법 (0) | 2022.12.29 |