
728x90
https://hyunsungstory.tistory.com/161
딥러닝 : Fashion mnist 10개로 분류된 패션 이미지를 tensorflow를 이용해 분류하기 / Flatten , softmax , 분
1. 이미지와 행렬 모든 이미지 사진은 픽셀당 숫자로 되어있습니다. 0~255까지 되어있고 0이 검정색, 255가 흰색입니다. 그 숫자의 데이터 타입은 Uint8(Unsigned int) 이라고 적습니다. 먼저 검정부터 회
hyunsungstory.tistory.com
위 게시글과 똑같은 데이터 셋으로 진행합니다.
바로 모델링 과정으로 넘어가겠습니다.
Flatten()라이브러리 없이 이미지를 평탄화 하는 방법
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import DropoutDropout이란 뉴런에 연결된 선을, 일부분을 잘라서, 학습이 잘 되도록 하는 방법
def build_model():
model = Sequential()
model.add( Dense(128, 'relu',input_shape=(784,)) )
model.add( Dropout(0.2) )
model.add( Dense(64, 'relu') )
model.add( Dense(10, 'softmax'))
model.compile('adam', 'sparse_categorical_crossentropy', ['accuracy'])
return model 이전 게시글에서는 input_shape을 사용하지 않고 flatten 라이브러리를 사용해서 처리를 했는데 그렇게 사용하지 않고
운영하는 회사들도 있기 때문에 ( 텐서플로우 버젼에 따라 다름 ) 위와 같이 코드를 작성 해보았다.
input_shape에 784가 들어간 이유는 아래 사진과 같다

Validation_data= 파라미터
에포크시마다 테스트를 하는 (쪽지시험이라고 생각) 밸리데이션 데이터를 처리하는 방법중에
밸리데이션 데이터를 따로 준비한 경우에 사용하는 validation_data= 파라미터가 있다.
model = build_model()
model.summary()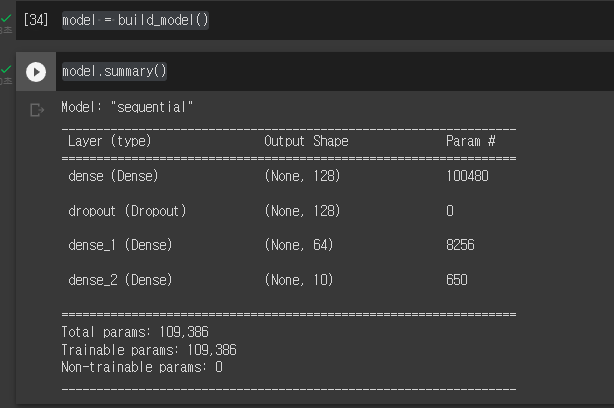
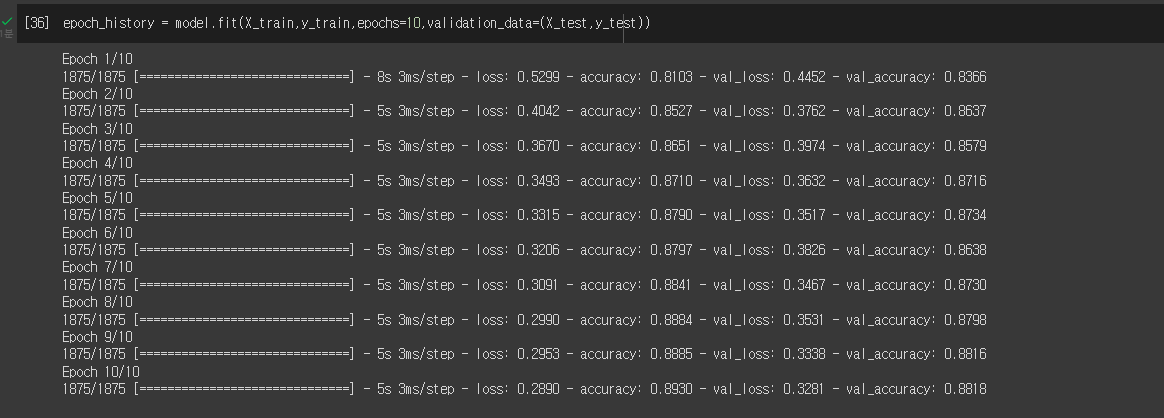
epoch_history = model.fit(X_train,y_train,epochs=10,validation_data=(X_test,y_test))validation_data= 을 쳐주고 그 뒤에 튜플 () 로 X_test값과 y_test값을 넣어주면 넣은 값으로 에포크시마다 테스트를 진행한다.
위 학습 결과의 history를 차트로 표현 하고 평가 과정을 하면
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.legend(['Train','Val'])
plt.show()

위와 같은 결과를 얻을 수 있다.
'인공지능 > 딥러닝' 카테고리의 다른 글
| 딥러닝 : 레이블링된 y값을 원핫 인코딩으로 바꾸기 tf.keras.utils.to_categorical() / Mnist 손글씨 숫자 예측 (0) | 2022.12.29 |
|---|---|
| 딥러닝 : Tensorflow의 모델을 저장하고 불러오는 방법 (0) | 2022.12.29 |
| 딥러닝 : Tensorflow의 콜백클래스를 이용해서 원하는 조건이 되면 학습을 멈추게 하기 (0) | 2022.12.29 |
| 딥러닝 : epochs의 횟수를 늘렸을 때 학습데이터/밸리데이션 데이터와 OverFitting (0) | 2022.12.29 |
| 딥러닝 : softmax로 나온 결과를 레이블 인코딩으로 바꾸는 방법 (0) | 2022.12.29 |