
PROBLEM STATEMENT
- 추천시스템은 영화나 노래등을 추천하는데 사용되며, 주로 관심사나 이용 내역을 기반으로 추천한다.
- 이 노트북에서는, Item-based Collaborative Filtering 으로 추천시스템을 구현한다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline필요 라이브러리 임포트
movie_titles_df = pd.read_csv('Movie_Id_Titles.csv')
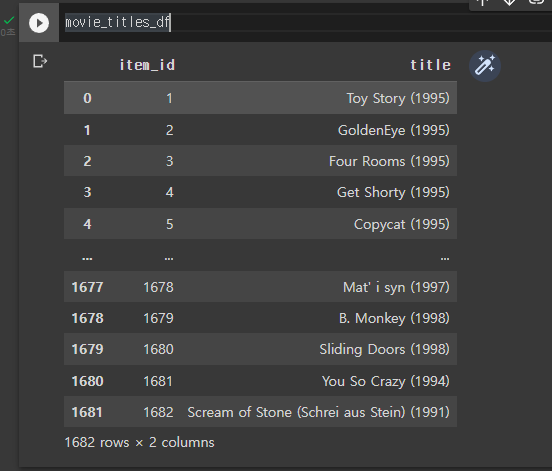
movie_titles_df데이터프레임을 불러온 후 변수로 저장해줍니다.
별점 데이터가 들어있고 탭으로 구분되어있고 컬럼이름이 없는 데이터파일을 불러옵니다
movies_rating_df =pd.read_csv('u.data',sep='\t',names=['user_id', 'item_id', 'rating', 'timestamp'])
# 탭으로 구분되어있으므로 sep='\t' // names=를 이용해서 컬럼이름 설정
movies_rating_df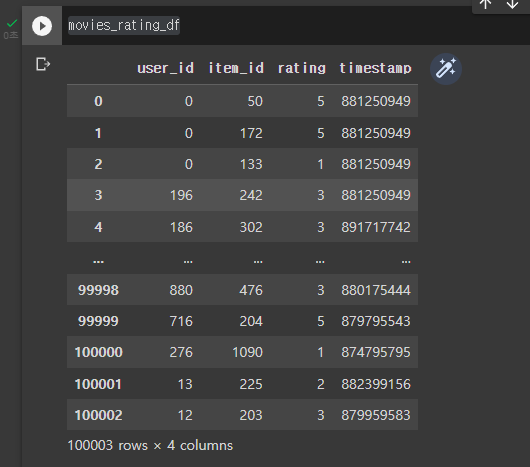
필요없는 컬럼을 삭제해줍니다 . ( timestamp )
movies_rating_df.drop('timestamp',axis=1,inplace=True)이후 두 개의 데이터 프레임을 합칠 것인데 pandas의 merge()를 이용하겠습니다.
movies_rating_df = pd.merge(movie_titles_df,movies_rating_df,on='item_id',
how='left')
movies_rating_df
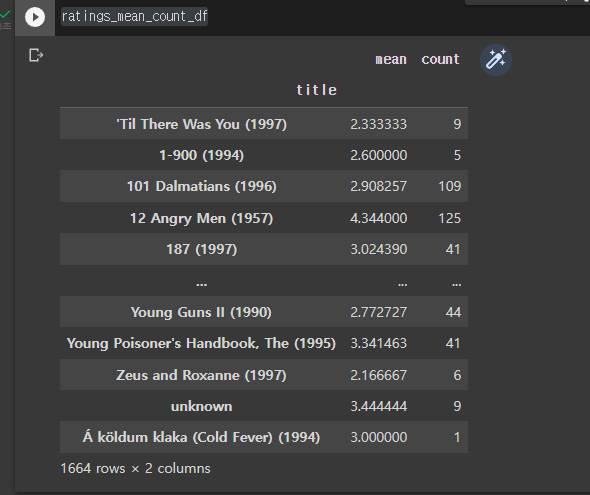
이후 각 영화별 별점의 평균과 카운트를 구하고, 이를 각각 ratings_df_mean, ratings_df_count에 저장하겠습니다
ratings_df_mean = movies_rating_df.groupby('title')['rating'].mean()
ratings_df_count = movies_rating_df.groupby('title')['rating'].count()join()
위 두 개의 데이터 프레임을 합치겠습니다. join()함수 이용
df1=ratings_df_mean.to_frame() # to_frame()를 이용하여 데이터프레임으로 만들어준다.
df1.columns = ['mean'] # 컬럼이름 변경
df2=ratings_df_count.to_frame()
df2.columns = ['count']
ratings_mean_count_df = df1.join(df2)
ratings_mean_count_df
pivot_table()
우선 전체 추천 시스템을 만들기 전에 영화 하나에대한 , ITEM-BASED COLLABORATIVE FILTERING을 수행하겠습니다.
pivot_table 이용
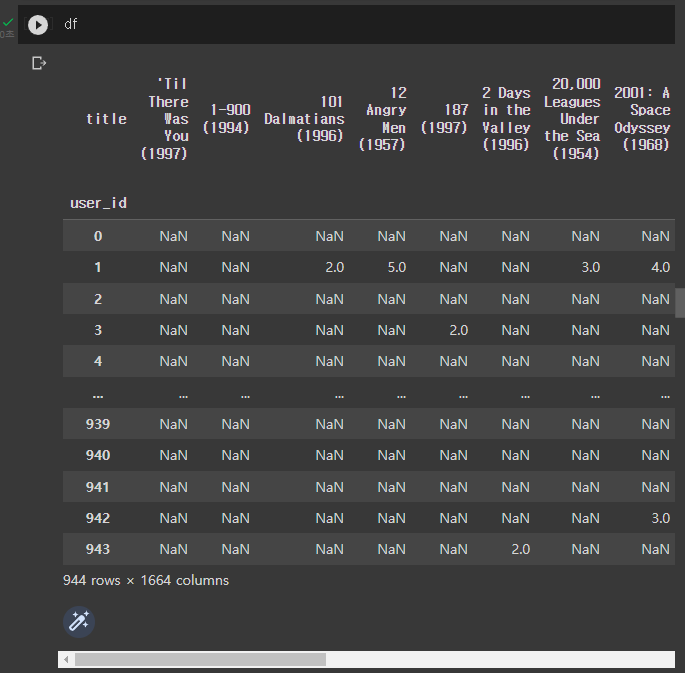
df = movies_rating_df.pivot_table(index='user_id',columns='title',values='rating',
aggfunc='mean')
# index는 user_id컬럼으로, columns는 title데이터로, values는 rating으로 채워주고 그 값은 평균으로 채운다df를 확인해보면 아래와 같습니다.
영화를 Titanic으로 정하고 전체 영화와 타이타닉 영화의 상관관계 분석을 하고 타이타닉을 본 사람들에게 상관계수가 높은 영화를 추천하면 될 것 같습니다.
corrwith 함수를 이용해서 상관계수를 뽑아보겠습니다.
corr_titanic = df.corrwith( df['Titanic (1997)'] )
corr_titanic=corr_titanic.to_frame()
corr_titanic.columns = ['correlation']
corr_titanic=corr_titanic.join(ratings_mean_count_df['count'])
corr_titanic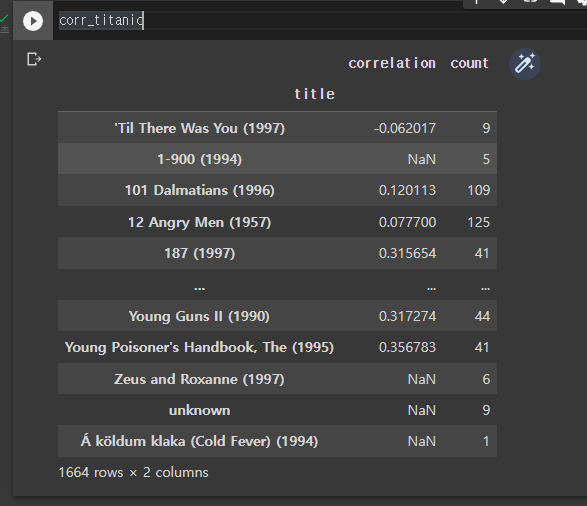
이후 결측치 제거와 상관계수 컬럼으로 정렬을 해 줍니다.
corr_titanic.dropna(inplace=True)
corr_titanic.sort_values('correlation',ascending=False)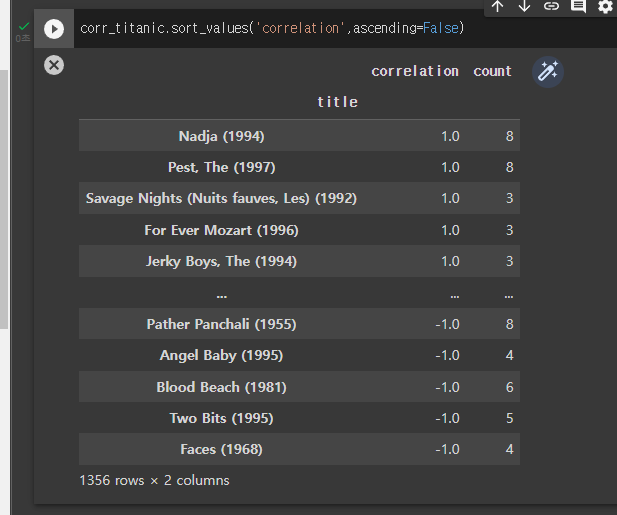
count가 상관계수는 높지만, count의 수가 너무 적은 것이 문제가 될 것 같습니다.
그래서 아래 코드에서 80명 이상이 별점을 준 영화들로만 추천을 하겠습니다.
corr_titanic.loc[corr_titanic['count'] >= 80,].sort_values('correlation',ascending=False).head(7)
전체 데이터셋에 대한 ITEM-BASED COLLABORATIVE FILTER
corr(min_periods=80)
위에서 했듯이 80명 이상이 별점을 준 영화만 상관계수를 뽑는 방법은 corr함수의 min_periods=파라미터를 사용하면 됩니다.
corr_movie = df.corr(min_periods=80)
위 사진과 같은 별점 정보 데이터프레임을 이용해서 영화 추천을 하는 코드를 작성을 해보겠습니다.
similar_movies_list = pd.DataFrame()
for i in range(myRatings.shape[0]):
movie_title=myRatings['Movie Name'][i]
recom_movies=corr_movie[movie_title].dropna().sort_values(ascending=False).to_frame()
recom_movies.columns = ['correlation']
recom_movies['weight'] = recom_movies['correlation'] * myRatings['Ratings'][i]
similar_movies_list=similar_movies_list.append(recom_movies)similar_movies_list=similar_movies_list.sort_values('weight',ascending=False)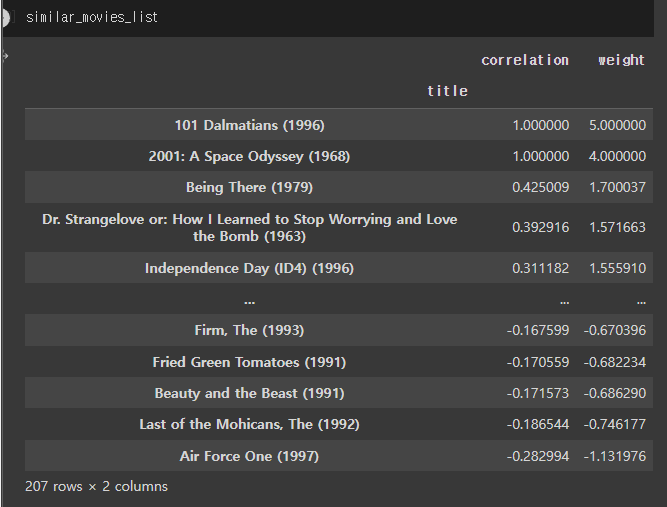
여기에서도 문제점 2개를 찾을 수 있습니다 첫 번째는 내가본 영화는 다시 추천할 수 없도록 데이터프레임에서 삭제를 해주어야 합니다. 그 코드를 작성 해보겠습니다.
drop_index_list = myRatings['Movie Name'].to_list()
for name in drop_index_list :
if name in similar_movies_list.index :
similar_movies_list.drop(name,axis=0,inplace=True)두 번째 문제는
# 중복데이터가 있는지 먼저 확인
similar_movies_list.reset_index()['title'].value_counts()
중복 데이터가 있음을 확인을 했으니 제거하는 코드를 아래에서 작성하겠습니다.
# 제거
similar_movies_list.groupby('title')['weight'].max().sort_values(ascending=False)
weight의 내림차순으로 정렬되어있고, 중복데이터도, 내가본 영화도 없는 추천 시스템을 개발 완료했습니다.
'Python' 카테고리의 다른 글
| Python enumerate() 내장함수 / 요소와 인덱스 함께 처리하기 (0) | 2023.10.05 |
|---|---|
| Python 파이썬으로 압축파일 푸는 방법 / zipfile (0) | 2022.12.30 |
| python파이썬 joblib 이용해 모델 저장하기 (0) | 2022.12.02 |
| Python파이썬 Google Map API - geocoding 설정,사용 (0) | 2022.11.30 |
| python파이썬 seaborn heatmap 사용하기, 여러 DataFrame 수치화 하기 (0) | 2022.11.30 |